[Update 2014/06/17: Remove XNA comparison, as it is not fair and relevant]
If you are working with a managed language like C# and you are concerned by performance, you probably know that, even if the Microsoft JIT CLR is quite efficient, It has a significant cost over a pure C++ implementation. If you don't know much about this cost, you have probably heard about a mean cost for managed languages around 15-20%. If you are really concern by this, and depending on the cases, you know that the reality of a calculation-intensive managed application is more often around x2 or even x3 slower than its C++ counterpart. In this post, I'm going to present a micro-benchmark that measure the cost of calling a native Direct3D 11 API from a C# application, using various API, ranging from SharpDX, SlimDX, WindowsCodecPack.
Why this benchmark is important? Well, if you intend like me to build some serious 3D games with a C# managed API (don't troll me on this! ;) ), you need to know exactly what is the cost of calling intensively a native Direct3D API (mainly, the cost of the interop between a managed language and a native API) from a managed language. If your game is GPU bounded, you are unlikely to see any differences here. But if you want to apply lots of effects, with various models, particles, materials, playing with several rendering targets and a heavy deferred rendering technique, you are likely to perform lots of draw calls to the Direct3D API. For a AAA game, those calls could be as high as 3000-7000 draw submissions in instancing scenarios (look at latest great DICE publications in "DirectX 11 Rendering in Battlefield 3" from Johan Andersson). If you are running at 60fps (or lower 30fps), you just have 17ms (or 34ms) per frame to perform your whole rendering. In this short time range, drawing calls can take a significant amount of time, and this is a main reason why multi-threading batching command were introduced in DirectX11. We won't use such a technique here, as we want to evaluate raw calls.
As you are going to see, results are pretty interesting for someone that is concerned by performance and writing C# games (or even efficient tools for a 3D Middleware)
The Managed (C#) to Native (C++) interop cost
When a managed application needs to call a native API, it needs to:
- Marshal method/function arguments from the managed world to the unmanaged world
- The CLR has to switch from a managed execution to an unmanaged environment (change exception handling, stacktrace state...etc.)
- The native methods is effectively called
- Than you have to marshal output arguments and results from unmanaged world to managed one.
- Using the default interop mechanism provided under C# is P/Invoke, which is in charge of performing all the previous steps. But P/Invoke comes at a huge cost when you have to pass some structures, arrays by values, strings...etc.
- Using a C++/CLI assembly that will perform a marshaling written by hand to the native C++ methods. This is used by SlimDX, WindowsCodePack and XNA.
- Using SharpDX technique that is generating all the marshaling and interop at compile time, in a structured and consistent way, using some missing CLR bytecode inside C# that is usually only available in C++/CLI
ID3D11DeviceContext::SetRenderTargets, you can see that marshaling takes a significant amount of code:/// <unmanaged>void ID3D11DeviceContext::OMSetRenderTargets([In] int NumViews,[In, Buffer, Optional] const ID3D11RenderTargetView** ppRenderTargetViews,[In, Optional] ID3D11DepthStencilView* pDepthStencilView)</unmanaged>
public void SetRenderTargets(int numViews, SharpDX.Direct3D11.RenderTargetView[] renderTargetViewsRef, SharpDX.Direct3D11.DepthStencilView depthStencilViewRef) {
unsafe {
IntPtr* renderTargetViewsRef_ = (IntPtr*)0;
if ( renderTargetViewsRef != null ) {
IntPtr* renderTargetViewsRef__ = stackalloc IntPtr[renderTargetViewsRef.Length];
renderTargetViewsRef_ = renderTargetViewsRef__;
for (int i = 0; i < renderTargetViewsRef.Length; i++)
renderTargetViewsRef_[i] = (renderTargetViewsRef[i] == null)? IntPtr.Zero : renderTargetViewsRef[i].NativePointer;
}
SharpDX.Direct3D11.LocalInterop.Callivoid(_nativePointer, numViews, renderTargetViewsRef_, (void*)((depthStencilViewRef == null)?IntPtr.Zero:depthStencilViewRef.NativePointer),((void**)(*(void**)_nativePointer))[33]);
}
}
Hopefully, in SharpDX unlike any other DirectX .NET APIs, this code has been written to be consistent over the whole generated code, and was carefully designed to be quite efficient... but still, It has obviously a cost, and we need to know it!
Protocol used for this micro-benchmark
Writing a benchmark is error prone, often subject to caution and relatively "narrow minded". Of course, this benchmark is not perfect, I just hope that It doesn't contain any mistake that would give false results trend!
In order for this test to be closer to a real 3D application usage, I made the choice to perform a very basic test on a sequence of draw calls that are usually involved in common drawing calls scenarios. This test consist of drawing triangles using 10 successive effects (Vertex Shaders/Pixel Shaders), with their own vertex buffers, setting the viewport and render target to the backbuffer. This loop is then ran thousand of times in order to get a correct average.
The SharpDX main loop is coded like this:
var clock = new Stopwatch();
clock.Start();
for (int j = 0; j < (CommonBench.NbTests + 1); j++)
{
for (int i = 0; i < CommonBench.NbEffects; i++)
{
context.InputAssembler.SetInputLayout(layout);
context.InputAssembler.SetPrimitiveTopology(PrimitiveTopology.TriangleList);
context.InputAssembler.SetVertexBuffers(0, vertexBufferBindings[i]);
context.VertexShader.Set(vertexShaders[i]);
context.Rasterizer.SetViewports(viewPort);
context.PixelShader.Set(pixelShaders[i]);
context.OutputMerger.SetTargets(renderView);
context.ClearRenderTargetView(renderView, blackColor);
context.Draw(3, 0);
}
if (j > 0 && (j % CommonBench.FlushLimit) == 0)
{
clock.Stop();
Console.Write("{0} ({3}) - Time per pass {1:0.000000}ms - {2:000}%\r", programName, (double)clock.ElapsedMilliseconds / (j * CommonBench.NbEffects), j * 100 / (CommonBench.NbTests), arch);
context.Flush();
clock.Start();
}
}
CommonBench.FlushLimit value was selected to avoid any stalls from the GPU.I have ported this benchmark under:
- C++, using raw native calls and Direct3D11 API
- SharpDX, using Direct3D11 running under Microsoft .NET CLR 4.0 and with Mono 2.10 (both trying llvm on/off). SharpDX is the only managed API to be able to run under Mono.
- SlimDX using Direct3D11 running under Microsoft .NET CLR 4.0. SlimDX is "NGENed" meaning that it is compiled to native code when you install it.
- WindowsCodePack 1.1 using Direct3D11 running under Microsoft .NET CLR 4.0
Results
You can see the raw results in the following table. Time is measured for the simple drawing sequence (inside the loop for(i) nbEffects). Lower is better. The ratio on the right indicates how much is slower the tested API compare to the C++ one. For example, SharpDX in x86 mode is running 1,52 slower than its pure C++ counterpart.
| Direct3D11 Simple Bench | x86 (ms) | x64 (ms) | x86-ratio | x64-ratio |
| Native C++ (MSVC VS2010) | 0.000386 | 0.000262 | x1.00 | x1.00 |
| Managed SharpDX (1.3 MS .Net CLR) | 0.000585 | 0.000607 | x1.52 | x2.32 |
| Managed SlimDX (June 2010 - Ngen) | 0.000945 | 0.000886 | x2.45 | x3.38 |
| Managed SharpDX (1.3 Mono-2.10) | 0.002404 | 0.001872 | x6.23 | x7.15 |
| Managed Windows API CodePack 1.1 | 0.002551 | 0.003219 | x6.61 | x12.29 |
And the associated graphs comparison both for x86 and x64 platforms:
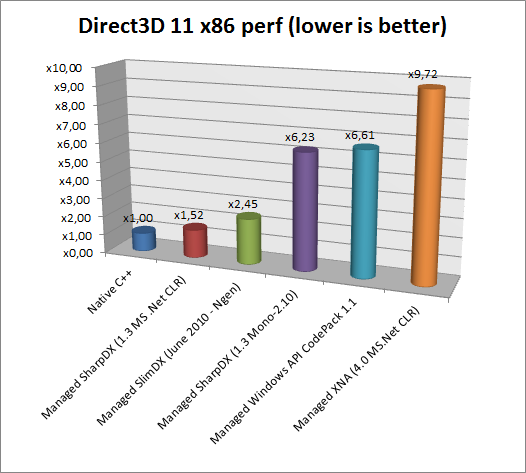

Results are pretty self explanatory. Although we can highlight some interesting facts:
- Managed Direct3D API calls are much slower than native API calls, ranging from x1.52 to x10 depending on the API you are using.
- SharpDX is providing the fastest Direct3D managed API, which is ranging only from x1.52 to x2.32 slower than C++, at least 50% faster than any other managed APIs.
- All other Direct3D managed API are significantly slower, ranging from x2.45 to x12.29
- Running this benchmark with SharpDX and Mono 2.10 is x6 to x7 times slower than SharpDX with Microsoft JIT (!)
This test could be also extrapolated to other parts of a 3D engine, as It will probably slower by a factor of x2 compare to a brute force C++ engine. For AAA game, this would be of course an unacceptable performance penalty, but If you are a small/independent studio, this cost is relatively low compare to the cost of efficiently developing a game in C#, and in the end, that's a trade-off.
In case you are using SharpDX API, you can still run at a reasonable performance. And if you really want to circumvent this interop cost for chatty API scenarios, you can design your engine to call a native function that will batch calls to the Direct3D native API.
You can download this benchmark Sharp3DBench.7z.